1. Introduction
There are many reasons why two houses might have different prices. To start with, one house might just be larger or have a better layout than the other. Let’s call these sorts of house-to-house differences “fine-grained”. But, prices can also vary for reasons that have nothing to do with the houses themselves. Even if two houses are physically identical, one house might sit in a more attractive neighborhood or belong to a better school district. Let’s call such differences over larger scales “coarse-grained”.
Different scales dominate in different places. In some counties, most of the price variation comes from fine-grained, house-to-house differences. Think about Los Angeles, CA where there is a lot of heterogeneity in the age and quality of the housing stock, even for houses that are right next door to one another. But, there are also coarse-grained counties where most of the house-price variation occurs over much larger scales. Think about Orange County, CA where the typical house is part of a subdivision. While there are lots of differences between subdivisions in Orange County, all the houses within each subdivision are typically built in a similar style by a single company at the exact same time.

This post shows how to estimate the characteristic scale of house-price variation in a county. That is, it shows how to tell if a county is fine-grained like Los Angeles, coarse-grained like Orange County, or somewhere in between. To do this, I introduce a new scale-specific variance estimator based on the Allan variance. This estimator decomposes the cross-sectional house-price variation in a given county into scale-specific components such as the amount of variation that arises from comparing randomly selected houses or the amount of variation that arises from comparing randomly selected neighborhoods.
Why not just compare the variance of the individual house prices to the variance of the neighborhood-level averages? The answer is simple: those calculations aren’t independent. Fine-grained counties with lots of house-to-house variation will mechanically have more variance in their average neighborhood-level prices. Just imagine the extreme case where all of the variation comes from house-to-house differences and each house’s price is independently drawn from the same normal distribution,  . In a world where the
. In a world where the  th neighborhood has
th neighborhood has  houses, the variance of the neighborhood-level average price,
houses, the variance of the neighborhood-level average price,  , would be increasing in the amount of house-to-house variation,
, would be increasing in the amount of house-to-house variation,  . I use this new scale-specific estimator because I don’t want to confuse these sorts of emergent neighborhood-level fluctuations with the honest-to-goodness neighborhood-level differences.
. I use this new scale-specific estimator because I don’t want to confuse these sorts of emergent neighborhood-level fluctuations with the honest-to-goodness neighborhood-level differences.
2. Data-Generating Process
Consider a county with  houses and
houses and  neighborhoods where there are
neighborhoods where there are  houses in each neighborhood so that
houses in each neighborhood so that  . Suppose that house prices are the sum of a neighborhood-level value and a house-level value,
. Suppose that house prices are the sum of a neighborhood-level value and a house-level value,
(1) 
with  and
and  . Think about neighborhood-level values as the quality of the local school district or the attractiveness of the nearby restaurant scene. This value is coarse-grained. You can have a mansion or a hovel in a nice school district. The house-level value, by contrast, relates to the characteristics of each particular house. This value is fine-grained.
. Think about neighborhood-level values as the quality of the local school district or the attractiveness of the nearby restaurant scene. This value is coarse-grained. You can have a mansion or a hovel in a nice school district. The house-level value, by contrast, relates to the characteristics of each particular house. This value is fine-grained.
Given this data-generating process, we know that a fraction
(2) 
of the variation in house prices comes from neighborhood-level differences. This is the object of interest in the current post. If  is close to
is close to  , then the county is dominated by coarse-grained variation in house prices and looks like Orange County, CA. If is close to
, then the county is dominated by coarse-grained variation in house prices and looks like Orange County, CA. If is close to  , then the county is dominated by fine-grained variation in house prices and looks more like Los Angeles, CA. In the analysis below, I’m going to show how to estimate in simulated data.
, then the county is dominated by fine-grained variation in house prices and looks more like Los Angeles, CA. In the analysis below, I’m going to show how to estimate in simulated data.
3. Naïve Estimate of λ
One way to estimate would be to look at a variance ratio. You might first compute the average price in each neighborhood,
(3) 
and then look at the ratio of the variance of the neighborhood-level average prices to the total house-price variance:
(4) 
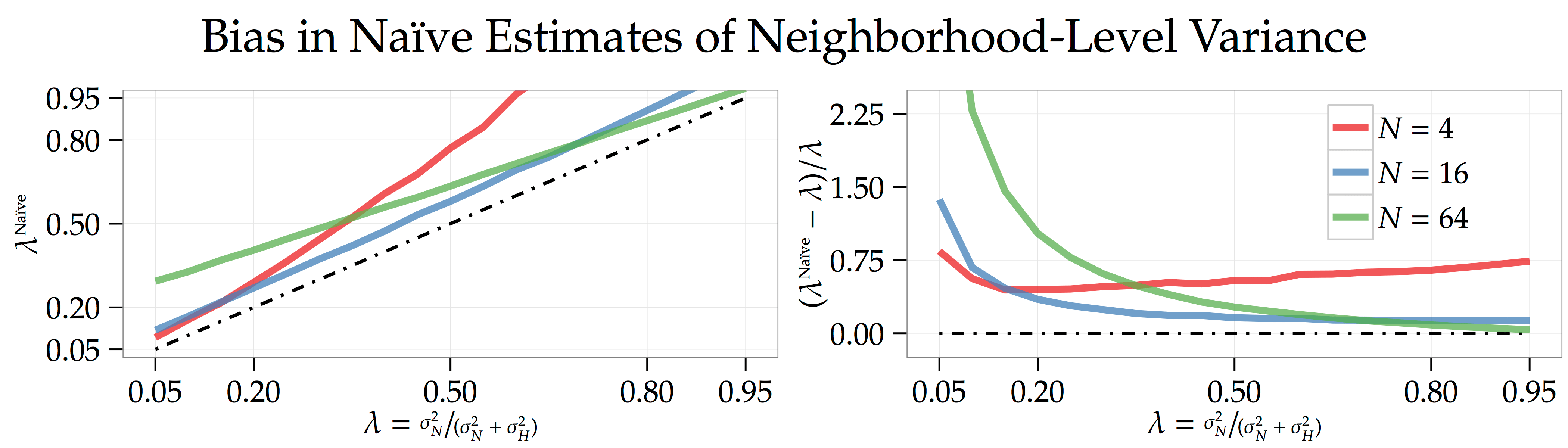
The thought process behind this calculation is really simple. If different neighborhoods have very different prices, then there should be a lot of variation in the average neighborhood-level price. In fact, it turns out to be too simple. While it is true that this naïve calculation will generate a higher in counties with lots of coarse-grained neighborhood-level variation, it will also be high in counties with lots of fine-grained house-to-house variation.
To see why, let’s look at the variance of the average price in each county:
(5) 
This variance consists of  parts: the true neighborhood-level variance,
parts: the true neighborhood-level variance,  ; differences in neighborhood-level prices from fine-grained variation,
; differences in neighborhood-level prices from fine-grained variation,  ; and, a correction for the unknown sample mean,
; and, a correction for the unknown sample mean,  . If we solve for the true amount of neighborhood-level variation,
. If we solve for the true amount of neighborhood-level variation,
(6) 
we see that it’s going to be smaller than the variation in neighborhood-level average prices. Counties with lots of fine-grained, house-to-house differences look like they have too much neighborhood-level house-price variation. What’s more, in the simulations plotted below [code] where the county has  houses, you can see that the nature of this bias is going to vary in a non-trivial way as the number of neighborhoods and the amount of coarse-grained, neighborhood-level variation changes.
houses, you can see that the nature of this bias is going to vary in a non-trivial way as the number of neighborhoods and the amount of coarse-grained, neighborhood-level variation changes.
4. Corrected Estimate of λ
In order to fix the problem, we need a way of simultaneously estimating neighborhood-level and house-level price variation and then using the second estimate to correct the bias in the first. It turns out that you can do this by running a simple cross-sectional regression,
(7) 
where  and
and  denote a collection of cleverly-chosen right-hand-side variables that I define below. The key insight is that, if you define these variables correctly, then you can read off both the neighborhood-level and house-level variation from the coefficients.
denote a collection of cleverly-chosen right-hand-side variables that I define below. The key insight is that, if you define these variables correctly, then you can read off both the neighborhood-level and house-level variation from the coefficients.
Here’s how. First, to create the variables that define the neighborhood-level variation, , randomly pair-off each neighborhood within the county so that there are  neighborhood pairs. Then create the variables:
neighborhood pairs. Then create the variables:
(8) ![\begin{align*} \mathbf{x}_1 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H - 1}{2 \cdot (\sfrac{H}{N})}\right)}} \times \left[ \begin{array}{ccc:ccc:ccc:ccc:c} 1 & \cdots & \phantom{-}1 & -1 & \cdots & -1 & 0 & \cdots & \phantom{-}0 & \phantom{-}0 & \cdots & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ \mathbf{x}_2 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H - 1}{2 \cdot (\sfrac{H}{N})}\right)}} \times \left[ \begin{array}{ccc:ccc:ccc:ccc:c} 0 & \cdots & \phantom{-}0 & \phantom{-}0 & \cdots & \phantom{-}0 & 1 & \cdots & \phantom{-}1 & -1 & \cdots & -1 & \cdots \end{array} \right]^{\top} \\ &\vdots \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-eb2c107de877921ae264726a20d7fcb6_l3.svg "Rendered by QuickLaTeX.com")
So, the first of these variables,  , compares the average price in the first neighborhood to the average price in the second neighborhood, meaning that the variable is mean zero. The scaling by
, compares the average price in the first neighborhood to the average price in the second neighborhood, meaning that the variable is mean zero. The scaling by  then ensures that
then ensures that  for all
for all  .
.
Next, to create the variables that define the house-level variation, , randomly pair-off each house within a neighborhood so that there are  house pairs within each neighborhood and
house pairs within each neighborhood and  pairs in total. Then, use these house pairs to create the variables:
pairs in total. Then, use these house pairs to create the variables:
(9) ![\begin{align*} \mathbf{y}_1 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left( \frac{H-1}{2 \cdot 1} \right)}} \times \left[ \begin{array}{ccccccc:c} 1 & -1 & 0 & \phantom{-}0 & \cdots & 0 & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ \mathbf{y}_2 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H-1}{2 \cdot 1}\right)}} \times \left[ \begin{array}{ccccccc:c} 0 & \phantom{-}0 & 1 & -1 & \cdots & 0 & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ &\vdots \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-209bb33660d8123092ee45afe20c9023_l3.svg "Rendered by QuickLaTeX.com")
So, the first of these variables,  , compares the price of the first house to the price of the second house, meaning that the variable is mean zero. The scaling by
, compares the price of the first house to the price of the second house, meaning that the variable is mean zero. The scaling by  ensures that
ensures that  for all
for all 
Because these right-hand-side variables are orthogonal to one another,
(10) 
we can then use their coefficients to estimate
(11) 
and thus generated an unbiased estimate of :
(12) 
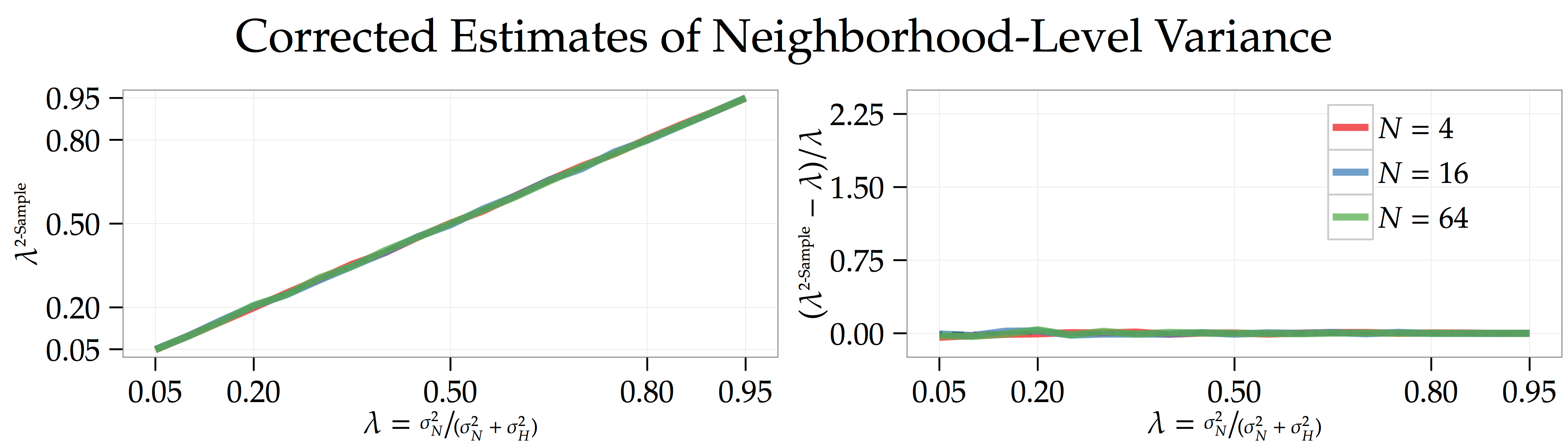
The simulations below [code] use the exact sample parameter values as above but calculate using this correction. All of the earlier bias disappears.
 months,
months,  , and then you have to use statistics to estimate this new predictor’s quality,
, and then you have to use statistics to estimate this new predictor’s quality,
 and
and  are estimated coefficients,
are estimated coefficients,  is the return on the
is the return on the  is the regression residual. If knowing
is the regression residual. If knowing  reveals a lot of information about what a stock’s future returns will be, then
reveals a lot of information about what a stock’s future returns will be, then  and the associated
and the associated  will be large.
will be large. of all NYSE-listed telecom stocks during a
of all NYSE-listed telecom stocks during a  -minute stretch on October
-minute stretch on October  th, 2010. Can you really fish this particular variable out from the sea of spurious predictors using intuition alone? And, how exactly are you supposed to do this in under
th, 2010. Can you really fish this particular variable out from the sea of spurious predictors using intuition alone? And, how exactly are you supposed to do this in under 
 is a stock’s return at time
is a stock’s return at time  ,
,  is a
is a  -dimensional vector of estimated coefficients,
-dimensional vector of estimated coefficients,  is the value of
is the value of  th predictor at time
th predictor at time  ,
,  is the number of time periods in the sample, and
is the number of time periods in the sample, and  —then this optimization problem would simply be an OLS regression.
—then this optimization problem would simply be an OLS regression.![\begin{align*} \hat{\vartheta}_q &= \mathrm{sgn}[\hat{\theta}_q] \cdot (|\hat{\theta}_q| - \lambda)_+. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-206d734626896d6c0cef0082f7318e46_l3.svg "Rendered by QuickLaTeX.com")
 represents what the standard OLS coefficient would have been if we had an infinite amount of data,
represents what the standard OLS coefficient would have been if we had an infinite amount of data, ![\mathrm{sgn}[x] = \sfrac{x}{|x|}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-006791ddd9fdb382b3c399e6ca4aca51_l3.svg "Rendered by QuickLaTeX.com") , and
, and  . On one hand, this solution means that, if OLS would have estimated a large coefficient,
. On one hand, this solution means that, if OLS would have estimated a large coefficient,  , then the LASSO is going to deliver a similar estimate,
, then the LASSO is going to deliver a similar estimate,  . On the other hand, the solution implies that, if OLS would have estimated a sufficiently small coefficient,
. On the other hand, the solution implies that, if OLS would have estimated a sufficiently small coefficient,  , then the LASSO is going to pick
, then the LASSO is going to pick  . Because the LASSO can set all but a handful of coefficients to zero, it can be used to identify the most important predictors even when the sample length is much shorter than the number of possible predictors,
. Because the LASSO can set all but a handful of coefficients to zero, it can be used to identify the most important predictors even when the sample length is much shorter than the number of possible predictors,  . Morally speaking, if only
. Morally speaking, if only  of the predictors are non-zero, then you should only need a few more than
of the predictors are non-zero, then you should only need a few more than  observations to select and then estimate the size of these few important coefficients.
observations to select and then estimate the size of these few important coefficients. simulations to show how to use the LASSO to forecast future returns. You can find all of the relevant code
simulations to show how to use the LASSO to forecast future returns. You can find all of the relevant code  stocks for
stocks for  periods. Each period, the returns of all
periods. Each period, the returns of all  stocks are governed by the returns of a subset of
stocks are governed by the returns of a subset of  stocks,
stocks,  , together with an idiosyncratic shock,
, together with an idiosyncratic shock,
 . This cast of
. This cast of  sparse signals changes over time, leading to the time subscript on
sparse signals changes over time, leading to the time subscript on  chance that each signal changes every period, so each signal lasts lasts
chance that each signal changes every period, so each signal lasts lasts  periods on average.
periods on average. to
to  , I estimate the LASSO on the first stock,
, I estimate the LASSO on the first stock,  , as defined in Equation (
, as defined in Equation ( periods of data where the
periods of data where the  possible predictors are the
possible predictors are the  periods of data, I then make an out-of-sample forecast in the
periods of data, I then make an out-of-sample forecast in the  st period.
st period.
 and
and  are estimated coefficients,
are estimated coefficients,  denotes the first stock’s realized return in period
denotes the first stock’s realized return in period  ,
,  denotes the LASSO’s forecast of the first stock’s return in minute
denotes the LASSO’s forecast of the first stock’s return in minute  and
and  represent the mean and standard deviation of this out-of-sample forecast from period
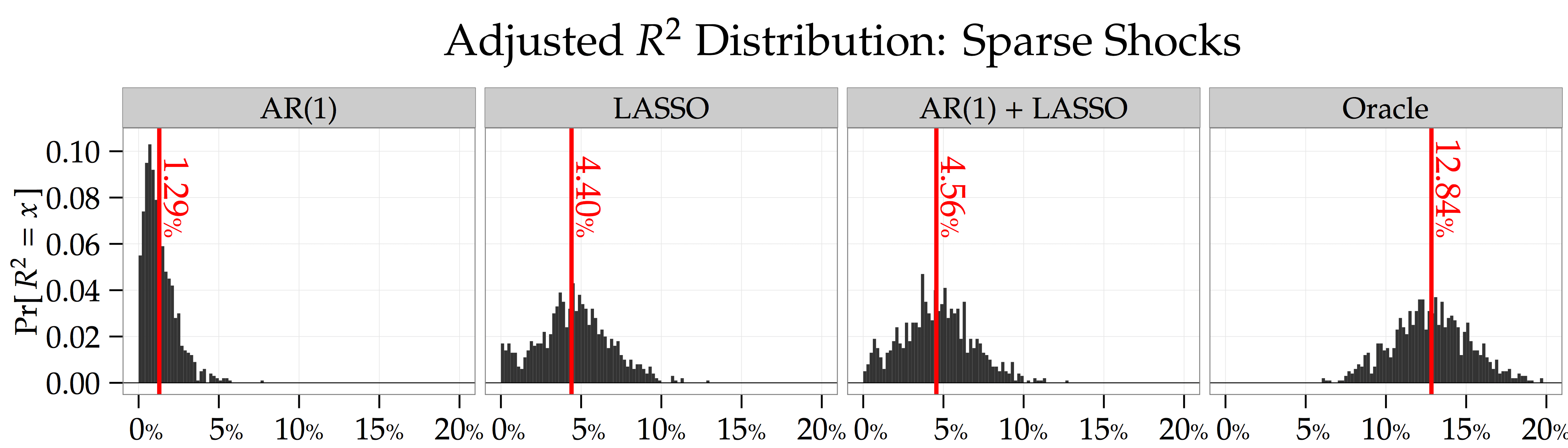
represent the mean and standard deviation of this out-of-sample forecast from period  is the regression residual. The figure below shows that the average adjusted-
is the regression residual. The figure below shows that the average adjusted- for the LASSO; whereas, this statistic is only
for the LASSO; whereas, this statistic is only  when making your return forecasts using an autoregressive model,
when making your return forecasts using an autoregressive model,
 periods of the data. This is why the forecasting regressions above only use data starting at
periods of the data. This is why the forecasting regressions above only use data starting at  . The figure below shows the distribution of penalty parameter choices across the
. The figure below shows the distribution of penalty parameter choices across the  jumps come from the discrete grid of possible
jumps come from the discrete grid of possible 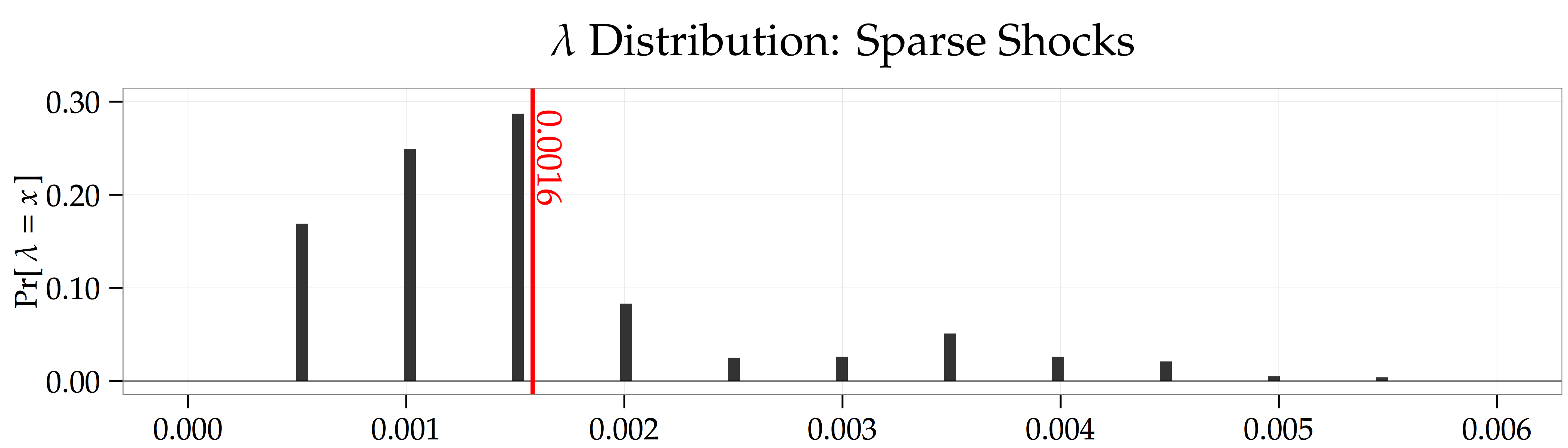
 . This is because the LASSO doesn’t do a perfect job of picking out the
. This is because the LASSO doesn’t do a perfect job of picking out the 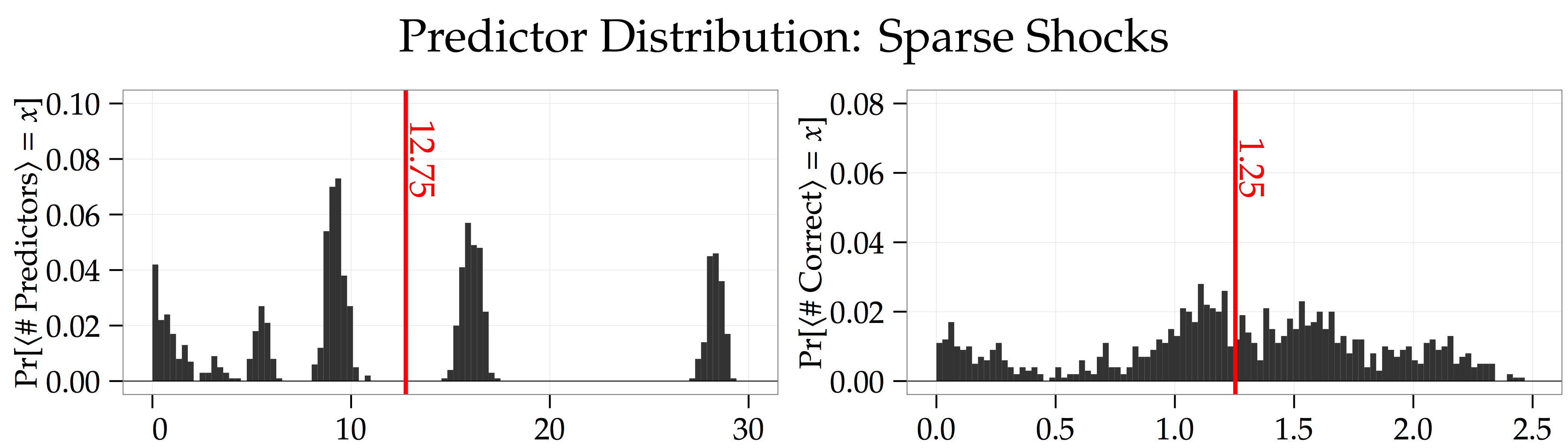

 . The figures below show that, in both these settings, the LASSO doesn’t add any forecasting power. Thus, running these simulations offers a pair of nice placebo tests showing that the LASSO really is picking up sparse signals in the cross-section of returns.
. The figures below show that, in both these settings, the LASSO doesn’t add any forecasting power. Thus, running these simulations offers a pair of nice placebo tests showing that the LASSO really is picking up sparse signals in the cross-section of returns.

 . This risky asset’s liquidation value is
. This risky asset’s liquidation value is  . For example, you might think about the asset as a stock that’ll have a value of
. For example, you might think about the asset as a stock that’ll have a value of  after some important news announcement tomorrow. It’s just that, right now, you don’t know which direction the news will go.
after some important news announcement tomorrow. It’s just that, right now, you don’t know which direction the news will go. shares of the risky asset. There are
shares of the risky asset. There are  uninformed speculators. Both informed and uninformed traders have an initial endowment of
uninformed speculators. Both informed and uninformed traders have an initial endowment of  (this is just a normalization) and exponential utility with risk-aversion parameter
(this is just a normalization) and exponential utility with risk-aversion parameter  ,
,
 denotes the number of shares demanded by a speculator.
denotes the number of shares demanded by a speculator. and has a demand schedule
and has a demand schedule  . That is, he has in mind a function which tells him how many shares to demand at each possible price,
. That is, he has in mind a function which tells him how many shares to demand at each possible price, 
 . Each uninformed speculator has a demand schedule
. Each uninformed speculator has a demand schedule  .
. for the
for the  informed speculators and
informed speculators and  for the
for the  uninformed speculators, and a price function
uninformed speculators, and a price function  such that (a) markets clear,
such that (a) markets clear,
![\begin{align*} X_{I,n}(p,\,s_n) &\in \arg \max_x \left\{ \, \mathrm{E}[ \, - \, \exp\left\{ \, \rho \cdot (v - p) \cdot x \right\} \, | \, p, \, s_n \, ] \, \right\} \text{ for all } n = 1, \, 2, \, \ldots, \, N \\ \text{and} \qquad X_{U,m}(p) &\in \arg \max_x \left\{ \, \mathrm{E}[ \, - \, \exp\left\{ \, \rho \cdot (v - p) \cdot x \right\} \, | \, p \, ] \, \right\} \text{ for all } m = 1, \, 2, \, \ldots, \, M. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-dec3a013ccd358cb9ef6f60b5b712619_l3.svg "Rendered by QuickLaTeX.com")
 . Prices will not be fully revealing due to the presence of noise-trader demand,
. Prices will not be fully revealing due to the presence of noise-trader demand, 



 . Next, I define the same object for informed and uninformed speculators. That is, taking the demand schedules of the other speculators as given, how much will the price change if the
. Next, I define the same object for informed and uninformed speculators. That is, taking the demand schedules of the other speculators as given, how much will the price change if the  th uninformed speculator increases his demand by
th uninformed speculator increases his demand by 
![\begin{align*} \tau_I = \left( \, \mathrm{Var}[v|p,\, s_n] \, \right)^{-1} = \tau_v + \tau_{\epsilon} + \varphi_I \times (N-1) \cdot \tau_{\epsilon} \quad \text{where} \quad \varphi_I = {\textstyle \frac{(N - 1) \cdot \gamma_I^2 \cdot \tau_z}{(N - 1) \cdot \gamma_I^2 \cdot \tau_z + \tau_{\epsilon}}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-7a4dd6120ac5c78d1c608c064d3dd276_l3.svg "Rendered by QuickLaTeX.com")
 represents the fraction of the precision from the other
represents the fraction of the precision from the other  informed speculators revealed to the
informed speculators revealed to the ![\begin{align*} \tau_U = \left( \, \mathrm{Var}[v|p] \, \right)^{-1} = \tau_v + \varphi_U \times N \cdot \tau_{\epsilon} \quad \text{where} \quad \varphi_U = {\textstyle \frac{N \cdot \gamma_I^2 \cdot \tau_z}{N \cdot \gamma_I^2 \cdot \tau_z + \tau_{\epsilon}}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-7edfd7377fd4b55cfa4c7d04f549957b_l3.svg "Rendered by QuickLaTeX.com")
 represents the fraction of the precision of the
represents the fraction of the precision of the  .
.![\begin{align*} \mathrm{E}[v|p, \, s_n] &= \left( {\textstyle \frac{\varphi_I }{\tau_I} \cdot \frac{\tau_{\epsilon}}{\gamma_I}} \right) \times \left( \, \lambda^{-1} \cdot p - \{N \cdot \alpha_I + M \cdot \alpha_U\} \, \right) + \left( {\textstyle \frac{(1 - \varphi_I) \cdot \gamma_I}{\tau_I} \cdot \frac{\tau_{\epsilon}}{\gamma_I}} \right) \times s_n \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-097898e8fed9bd26a5424a7e5526c10e_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} \mathrm{E}[v|p] &= \left( {\textstyle \frac{\varphi_U}{\tau_U} \cdot \frac{\tau_{\epsilon}}{\gamma_I}} \right) \times \left( \, \lambda^{-1} \cdot p - \{N \cdot \alpha_I + M \cdot \alpha_U\} \, \right). \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-a3e304a5f51bd665ded8b6c24d9323a0_l3.svg "Rendered by QuickLaTeX.com")
 . He then solves the optimization problem below,
. He then solves the optimization problem below,![\begin{align*} \max_x \left\{ \, (\mathrm{E}[v|\hat{p}_{I,n}, \, s_n] - \hat{p}_{I,n}) \cdot x - (\lambda_I + {\textstyle \frac{\rho}{2}} \cdot \mathrm{Var}[v|\hat{p}_{I,n}, \, s_n]) \cdot x^2 \, \right\} \quad \Rightarrow \quad x = {\textstyle \frac{\mathrm{E}[v|\hat{p}_{I,n}, \, s_n] - \hat{p}_{I,n}}{2 \cdot \lambda_I + \rho \cdot \mathrm{Var}[v|\hat{p}_{I,n}, \, s_n]}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-291d52ead0c8c7e1bfdc5be2dae04c33_l3.svg "Rendered by QuickLaTeX.com")
 . So, after a little bit of rearranging, we can write the informed speculators’ optimal demand schedules as
. So, after a little bit of rearranging, we can write the informed speculators’ optimal demand schedules as![\begin{align*} X_I(p,\,s_n) &= {\textstyle \frac{\mathrm{E}[v|p, \, s_n] - p}{\lambda_I + \sfrac{\rho}{\tau_I}}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-7d6d7f1d49a06aa555de4e753106203d_l3.svg "Rendered by QuickLaTeX.com")
 . He then solves the optimization problem below,
. He then solves the optimization problem below,![\begin{align*} \max_x \left\{ \, (\mathrm{E}[v|\hat{p}_U] - \hat{p}_U) \cdot x - (\lambda_U + {\textstyle \frac{\rho}{2}} \cdot \mathrm{Var}[v|\hat{p}_U]) \cdot x^2 \, \right\} \quad \Rightarrow \quad x = {\textstyle \frac{\mathrm{E}[v|\hat{p}_U] - \hat{p}_U}{2 \cdot \lambda_U + \rho \cdot \mathrm{Var}[v|\hat{p}_U]}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-4daf9888d1ad2fd166b3d5c0ce7b60c5_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} X_U(p) &= {\textstyle \frac{\mathrm{E}[v|p] - p}{\lambda_U + \sfrac{\rho}{\tau_U}}}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-185957a8c195ab1f22ce47bea6088066_l3.svg "Rendered by QuickLaTeX.com")

 as a result of a higher signal realization,
as a result of a higher signal realization,  , and prices move by a factor of
, and prices move by a factor of  for every
for every  .
.
 : if noise traders demand
: if noise traders demand  captures the amount of additional trading that each uninformed speculator does in response to a
captures the amount of additional trading that each uninformed speculator does in response to a  ,
,  ,
,  , and
, and  . This equilibrium is characterized by a system of
. This equilibrium is characterized by a system of  equations and
equations and  , subject to the constraints that
, subject to the constraints that  ,
,  ,
,  , and
, and  .
.
 , via the endogenous parameter
, via the endogenous parameter 
 , to the product of how uninformative prices are about other informed speculators’ signals,
, to the product of how uninformative prices are about other informed speculators’ signals,  , and how little each informed speculator has to trade in response to a
, and how little each informed speculator has to trade in response to a  . After all, if informed speculators don’t have to trade that often—i.e.,
. After all, if informed speculators don’t have to trade that often—i.e.,  —and prices don’t really reveal much of their private signal to other informed speculators when they do—i.e.,
—and prices don’t really reveal much of their private signal to other informed speculators when they do—i.e.,  , then prices shouldn’t be moving that much in response to private shocks—i.e.,
, then prices shouldn’t be moving that much in response to private shocks—i.e.,  .
. ,
,
 is big), when they are closer to risk neutral (i.e.,
is big), when they are closer to risk neutral (i.e.,  is small), when prices don’t reveal much about their private signal to other informed speculators (i.e.,
is small), when prices don’t reveal much about their private signal to other informed speculators (i.e.,  ), or when prices don’t move much when informed speculators trade on their private information (i.e.,
), or when prices don’t move much when informed speculators trade on their private information (i.e.,  because
because  ). Notice that this last effect is second order when
). Notice that this last effect is second order when  is small.
is small. , via the endogenous parameter
, via the endogenous parameter 
 —that is, if there are lots of small uninformed speculators. What’s more, we know from Equation (
—that is, if there are lots of small uninformed speculators. What’s more, we know from Equation (

 .
. ,
,  ,
,  ,
,  , and
, and  as the precision of noise-trader demand volatility ranges from
as the precision of noise-trader demand volatility ranges from  to
to  . You can find the code
. You can find the code 


 per month over the next
per month over the next  , and
, and  months and strategies which hold stocks for the next
months and strategies which hold stocks for the next  different hypothesis tests,
different hypothesis tests,  . Let
. Let  if the
if the  if the
if the  denote the p-value associated with some test statistic for the
denote the p-value associated with some test statistic for the  . But, if there are many tests, then this no longer works. If you look at a lot of hypotheses, then
. But, if there are many tests, then this no longer works. If you look at a lot of hypotheses, then  of the p-values should be less than
of the p-values should be less than  even if
even if 
 hypothesis tests, then only reject the null at the
hypothesis tests, then only reject the null at the  rather than
rather than  observations from
observations from  , but not all of the sample have the same mean.
, but not all of the sample have the same mean.  have a mean of
have a mean of  , and the rest have a mean of
, and the rest have a mean of  . The figure below shows that, if we use the Bonferroni method to identify which of the
. The figure below shows that, if we use the Bonferroni method to identify which of the  samples have a non-zero mean, then we’re only going to choose
samples have a non-zero mean, then we’re only going to choose  samples. But, by construction, we know that
samples. But, by construction, we know that  samples had a non-zero mean! We should be rejecting the null
samples had a non-zero mean! We should be rejecting the null 
 as the total number hypotheses that you reject at the
as the total number hypotheses that you reject at the  as the number of hypotheses that you reject at the
as the number of hypotheses that you reject at the ![\begin{align*} \mathit{FDR} = \mathrm{E}\left[ \, \sfrac{R_f}{R} \, \right]. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-0b1a06343212fa4f7af1e967846c3b6a_l3.svg "Rendered by QuickLaTeX.com")
 . If we wanted a false-discovery rate
. If we wanted a false-discovery rate  , then this test could produce at most
, then this test could produce at most  . If the test identified only half of the
. If the test identified only half of the  ,
,  , then this test could produce at most
, then this test could produce at most  .
.
 as
as

 , guaranteed. If we apply the false-discovery-rate procedure to the same numerical example from above using the
, guaranteed. If we apply the false-discovery-rate procedure to the same numerical example from above using the  threshold, then we see that as the number of hypotheses gets large,
threshold, then we see that as the number of hypotheses gets large,  , the fraction of rejected null hypotheses hovers around
, the fraction of rejected null hypotheses hovers around  . Improvement! It’s no longer shrinking to
. Improvement! It’s no longer shrinking to 
 of your null hypotheses. Let’s explore the proof of this result from
of your null hypotheses. Let’s explore the proof of this result from  . However, if you have a useful test statistic, then if
. However, if you have a useful test statistic, then if  that is more concentrated around
that is more concentrated around 
![\begin{align*} \mathit{FDR}(x) = \mathrm{E}\left[ \, \frac{ {\textstyle \sum_{n=1}^N} 1_{\{ p_n \leq x\}} \times 1_{\{ h_n = 0 \}} }{ {\textstyle \sum_{n=1}^N} 1_{\{ p_n \leq x \}} } \, \right] &= \frac{ \mathrm{E}\left[ \, {\textstyle \sum_{n=1}^N} 1_{\{ p_n \leq x\}} \times 1_{\{ h_n = 0 \}} \, \right] }{ \mathrm{E}\left[ \, {\textstyle \sum_{n=1}^N} 1_{\{ p_n \leq x \}} \, \right] } + \mathrm{O}\left( {\textstyle \frac{1}{\sqrt{N}}} \right) \\ &= \frac{ N \cdot \mathrm{Pr}( p_n \leq x | h_n = 0 ) \cdot \mathrm{Pr}(h_n = 0) }{ N \cdot \mathrm{G}(x) } + \mathrm{O}\left( {\textstyle \frac{1}{\sqrt{N}}} \right) \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-0ee214f596f97b5642e850fbbb4ee562_l3.svg "Rendered by QuickLaTeX.com")
 and
and  denotes
denotes  . Thus, we can simplify even further:
. Thus, we can simplify even further:
 . If we do this, then
. If we do this, then  and
and

 , then our false-discovery rate is capped at
, then our false-discovery rate is capped at 
 . Using MSA- or county-level data gives similar results. If prices were growing faster than usual last month, then they’ll be growing faster than usual next month as well.
. Using MSA- or county-level data gives similar results. If prices were growing faster than usual last month, then they’ll be growing faster than usual next month as well.
 houses. Let
houses. Let  denote the average value of owning a home in this Zip code at time
denote the average value of owning a home in this Zip code at time 
 . For example, one month a park might get built (a positive shock), the next month a nearby grocery store might close (a negative shock), and so on… In the analysis below, I use the
. For example, one month a park might get built (a positive shock), the next month a nearby grocery store might close (a negative shock), and so on… In the analysis below, I use the  notation to denote the Zip-code-level average of
notation to denote the Zip-code-level average of  . By contrast, if you’re thinking about Santa Monica, CA where the housing stock is very heterogeneous, then
. By contrast, if you’re thinking about Santa Monica, CA where the housing stock is very heterogeneous, then  . Each aggregate Zip-code-level shock is the average of the shocks to each of the
. Each aggregate Zip-code-level shock is the average of the shocks to each of the 
 . For example, the grocery-storing-closing shock might be a really negative shock for the part of the Zip code closest to the store, but only a minor inconvenience for the part of the Zip code farthest from the store who only shopped there occasionally.
. For example, the grocery-storing-closing shock might be a really negative shock for the part of the Zip code closest to the store, but only a minor inconvenience for the part of the Zip code farthest from the store who only shopped there occasionally.![\bar{\epsilon}_{[t-1]+K}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-417e3ae78b14342c66df0fe2a94db435_l3.svg "Rendered by QuickLaTeX.com") , that is, the Zip-code-level shock that will occur at time
, that is, the Zip-code-level shock that will occur at time ![([t-1]+K)](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-06ab1efed4f22b13bbad6d3d80711010_l3.svg "Rendered by QuickLaTeX.com") . But, buyers don’t get to see the full shock right away. A randomly selected group of
. But, buyers don’t get to see the full shock right away. A randomly selected group of  buyers will see the signal for the first kind of house,
buyers will see the signal for the first kind of house, ![\epsilon_{1,[t-1]+K}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-2a079298f58dc60d643ae4f6804bc316_l3.svg "Rendered by QuickLaTeX.com") , another randomly selected group of
, another randomly selected group of ![\epsilon_{2,[t-1]+K}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-cafe64da0ffc3bbbfd75e25d2ebba7cb_l3.svg "Rendered by QuickLaTeX.com") , and so on… until the
, and so on… until the ![\epsilon_{K,[t-1]+K}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-0a850717b300ff08fd8eba3bd56cef33_l3.svg "Rendered by QuickLaTeX.com") . So, each of the signals about the Zip code’s time
. So, each of the signals about the Zip code’s time  th of the buyers at time
th of the buyers at time  th of the buyers at time
th of the buyers at time  , and how many shares of the riskless asset to buy,
, and how many shares of the riskless asset to buy,  , in order to maximize their time
, in order to maximize their time  ,
,![\begin{align*} \max_{(x_{b,t}, \, y_{b,t})_{t=1}^T} \, \mathrm{E}_{b,t}[ \, - \exp\{ \, - \rho \cdot w_{b,T} \, \} \, ] \quad \text{s.t.} \quad w_0 \geq \bar{p}_t \cdot x_{b,t} + y_{b,t}. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-ef2ab3e51f32a2f396bde16d856cc3e1_l3.svg "Rendered by QuickLaTeX.com")
 .
.![\begin{align*} \bar{p}_t^{\text{rational}} &= \bar{v}_{[t-1]+K} - \mathrm{f}(\rho) \cdot \psi \\ &= \bar{v}_{t-1} + {\textstyle \sum_{k=0}^{K-1}} \bar{\epsilon}_{t+k} - \mathrm{f}(\rho) \cdot \psi, \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-2bf3bf2b72852b5865088176ff5d3819_l3.svg "Rendered by QuickLaTeX.com")
 is a function of the home buyers’ risk-aversion parameter. This is why you need the random-asset-supply assumption in models like
is a function of the home buyers’ risk-aversion parameter. This is why you need the random-asset-supply assumption in models like ![\begin{align*} \mathrm{Cov}[\Delta \bar{p}_t^{\text{rational}}, \, \Delta \bar{p}_{t-1}^{\text{rational}}] = 0, \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-6c21a30804b00f378b3dac329afefd2f_l3.svg "Rendered by QuickLaTeX.com")


![\begin{align*} \frac{ \mathrm{Cov}[\Delta \bar{p}_t^{\text{na\"{i}ve}}, \, \Delta \bar{p}_{t-1}^{\text{na\"{i}ve}}] }{ \mathrm{Var}[\Delta \bar{p}_{t-1}^{\text{na\"{i}ve}}] } &= \frac{K-1}{K} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-2dd1db1c1d4eb0f7bec74b8db45064cb_l3.svg "Rendered by QuickLaTeX.com")
You must be logged in to post a comment.