1. Motivating Example
A Popular Goal. Financial economists have been looking for variables that predict stock returns for as long as there have been financial economists. For some recent examples, think about Jegadeesh and Titman (1993), which shows that a stock’s current returns are predicted by the stock’s returns over the previous  months, Hou (2007), which shows that the current returns of smallest stocks in an industry are predicted by the lagged returns of the largest stocks in the industry, and Cohen and Frazzini (2008), which shows that a stock’s current returns are predicted by the lagged returns of its major customers.
months, Hou (2007), which shows that the current returns of smallest stocks in an industry are predicted by the lagged returns of the largest stocks in the industry, and Cohen and Frazzini (2008), which shows that a stock’s current returns are predicted by the lagged returns of its major customers.
Two-Step Process. When you think about it, finding these sorts of variables actually consists of two separate problems, identification and estimation. First, you have to use your intuition to identify a new predictor,  , and then you have to use statistics to estimate this new predictor’s quality,
, and then you have to use statistics to estimate this new predictor’s quality,
(1) 
where  and
and  are estimated coefficients,
are estimated coefficients,  is the return on the
is the return on the  th stock, and
th stock, and  is the regression residual. If knowing
is the regression residual. If knowing  reveals a lot of information about what a stock’s future returns will be, then
reveals a lot of information about what a stock’s future returns will be, then  and the associated
and the associated  will be large.
will be large.
Can’t Always Use Intuition. But, modern financial markets are big, fast, and dense. Predictability doesn’t always occur at scales that are easy for people to intuit, making the standard approach to tackling the first problem problematic. For instance, the lagged returns of the Federal Signal Corporation were a significant predictor for more than  of all NYSE-listed telecom stocks during a
of all NYSE-listed telecom stocks during a  -minute stretch on October
-minute stretch on October  th, 2010. Can you really fish this particular variable out from the sea of spurious predictors using intuition alone? And, how exactly are you supposed to do this in under minutes?
th, 2010. Can you really fish this particular variable out from the sea of spurious predictors using intuition alone? And, how exactly are you supposed to do this in under minutes?
Using Statistics Instead. In a recent working paper (link), Mao Ye, Adam Clark-Joseph, and I show how to replace this intuition step with statistics and use the least absolute shrinkage and selection operator (LASSO) to identify rare, short-lived, “sparse” signals in the cross-section of returns. This post uses simulations to show how the LASSO can be used to forecast returns.
2. Using the LASSO
LASSO Definition. The LASSO is a penalized-regression technique that was was introduced in Tibshirani (1996). It simultaneously identifies and estimates the most important coefficients using a far shorter sample period by betting on sparsity—that is, by assuming only a handful of variables actually matter at any point in time. Formally, using the LASSO means solving the problem below,
(2) 
where  is a stock’s return at time
is a stock’s return at time  ,
,  is a
is a  -dimensional vector of estimated coefficients,
-dimensional vector of estimated coefficients,  is the value of
is the value of  th predictor at time
th predictor at time  ,
,  is the number of time periods in the sample, and
is the number of time periods in the sample, and  is a penalty parameter. Equation (2) looks complicated at first, but it’s not. It’s a simple extension of an OLS regression. In fact, if you ignore the right-most term—the penalty function,
is a penalty parameter. Equation (2) looks complicated at first, but it’s not. It’s a simple extension of an OLS regression. In fact, if you ignore the right-most term—the penalty function,  —then this optimization problem would simply be an OLS regression.
—then this optimization problem would simply be an OLS regression.
Penalty Function. But, it’s this penalty function that’s the secret to the LASSO’s success, allowing the estimator to give preferential treatment to the largest coefficients and completely ignore the smaller ones. To better understand how the LASSO does this, consider the solution to Equation (2) when the right-hand-side variables are uncorrelated and have unit variance:
(3) ![\begin{align*} \hat{\vartheta}_q &= \mathrm{sgn}[\hat{\theta}_q] \cdot (|\hat{\theta}_q| - \lambda)_+. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-206d734626896d6c0cef0082f7318e46_l3.svg "Rendered by QuickLaTeX.com")
Here,  represents what the standard OLS coefficient would have been if we had an infinite amount of data,
represents what the standard OLS coefficient would have been if we had an infinite amount of data, ![\mathrm{sgn}[x] = \sfrac{x}{|x|}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-006791ddd9fdb382b3c399e6ca4aca51_l3.svg "Rendered by QuickLaTeX.com") , and
, and  . On one hand, this solution means that, if OLS would have estimated a large coefficient,
. On one hand, this solution means that, if OLS would have estimated a large coefficient,  , then the LASSO is going to deliver a similar estimate,
, then the LASSO is going to deliver a similar estimate,  . On the other hand, the solution implies that, if OLS would have estimated a sufficiently small coefficient,
. On the other hand, the solution implies that, if OLS would have estimated a sufficiently small coefficient,  , then the LASSO is going to pick
, then the LASSO is going to pick  . Because the LASSO can set all but a handful of coefficients to zero, it can be used to identify the most important predictors even when the sample length is much shorter than the number of possible predictors,
. Because the LASSO can set all but a handful of coefficients to zero, it can be used to identify the most important predictors even when the sample length is much shorter than the number of possible predictors,  . Morally speaking, if only
. Morally speaking, if only  of the predictors are non-zero, then you should only need a few more than
of the predictors are non-zero, then you should only need a few more than  observations to select and then estimate the size of these few important coefficients.
observations to select and then estimate the size of these few important coefficients.
3. Simulation Analysis
I run  simulations to show how to use the LASSO to forecast future returns. You can find all of the relevant code here.
simulations to show how to use the LASSO to forecast future returns. You can find all of the relevant code here.
Data Simulation. Each simulation involves generating returns for  stocks for
stocks for  periods. Each period, the returns of all
periods. Each period, the returns of all  stocks are governed by the returns of a subset of
stocks are governed by the returns of a subset of  stocks,
stocks,  , together with an idiosyncratic shock,
, together with an idiosyncratic shock,
(4) 
where  . This cast of
. This cast of  sparse signals changes over time, leading to the time subscript on . Specifically, I assume that there is a
sparse signals changes over time, leading to the time subscript on . Specifically, I assume that there is a  chance that each signal changes every period, so each signal lasts lasts
chance that each signal changes every period, so each signal lasts lasts  periods on average.
periods on average.
Fitting Models to the Data. For each period from  to
to  , I estimate the LASSO on the first stock,
, I estimate the LASSO on the first stock,  , as defined in Equation (2) using the previous
, as defined in Equation (2) using the previous  periods of data where the
periods of data where the  possible predictors are the stocks. This means using time periods to estimate a model with potential right-hand-side variables. As useful benchmarks, I also estimate the autoregressive model from Equation (1) and an oracle regression. In this specification, I estimate an OLS regression with the true predictors as the right-hand-side variables. Obviously, in the real-world you don’t know what the true predictors are, but this specification gives an estimate of the best fit you could achieve. After fitting each model to the previous
possible predictors are the stocks. This means using time periods to estimate a model with potential right-hand-side variables. As useful benchmarks, I also estimate the autoregressive model from Equation (1) and an oracle regression. In this specification, I estimate an OLS regression with the true predictors as the right-hand-side variables. Obviously, in the real-world you don’t know what the true predictors are, but this specification gives an estimate of the best fit you could achieve. After fitting each model to the previous  periods of data, I then make an out-of-sample forecast in the
periods of data, I then make an out-of-sample forecast in the  st period.
st period.
Forecasting Regressions. I then check how closely these forecasts line up with the realized returns of the first asset by analyzing the adjusted statistics from a bunch of forecasting regressions. For example, I take the LASSO’s return forecast in periods to and estimate the regression below,
(5) 
where  and
and  are estimated coefficients,
are estimated coefficients,  denotes the first stock’s realized return in period
denotes the first stock’s realized return in period  ,
,  denotes the LASSO’s forecast of the first stock’s return in minute ,
denotes the LASSO’s forecast of the first stock’s return in minute ,  and
and  represent the mean and standard deviation of this out-of-sample forecast from period to , and
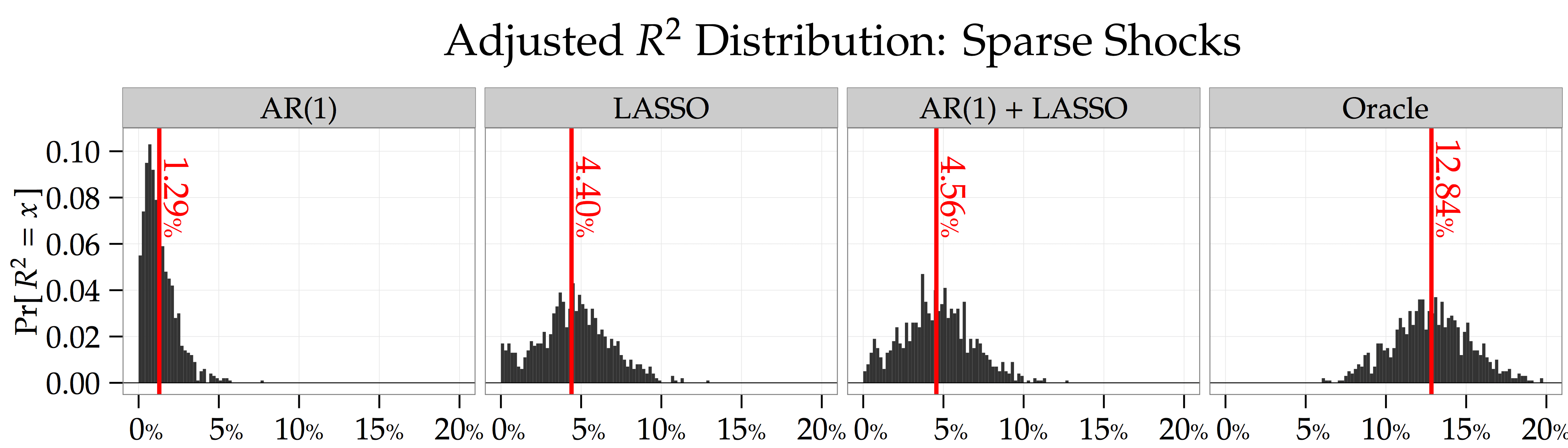
represent the mean and standard deviation of this out-of-sample forecast from period to , and  is the regression residual. The figure below shows that the average adjusted- statistic from simulations is
is the regression residual. The figure below shows that the average adjusted- statistic from simulations is  for the LASSO; whereas, this statistic is only
for the LASSO; whereas, this statistic is only  when making your return forecasts using an autoregressive model,
when making your return forecasts using an autoregressive model,
(6) 
4. Tuning Parameter
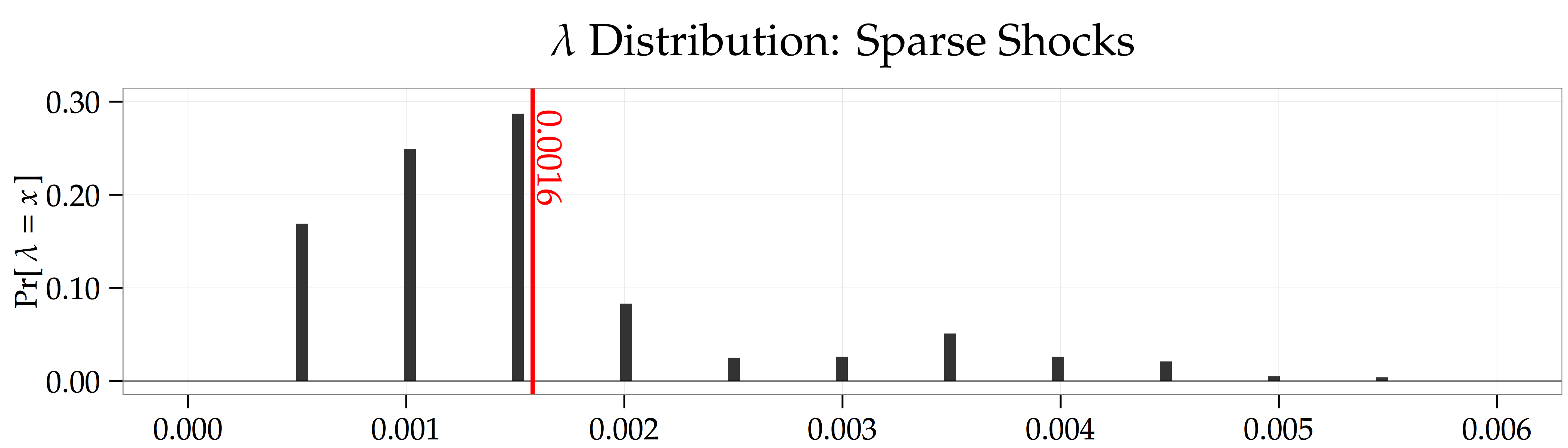
Penalty Parameter Choice. Fitting the LASSO to the data involves selecting a penalty parameter, . I do this by selecting the penalty parameter that has the highest out-of-sample forecasting during the first  periods of the data. This is why the forecasting regressions above only use data starting at instead of
periods of the data. This is why the forecasting regressions above only use data starting at instead of  . The figure below shows the distribution of penalty parameter choices across the simulations. The discrete
. The figure below shows the distribution of penalty parameter choices across the simulations. The discrete  jumps come from the discrete grid of possible s that I considered when running the code.
jumps come from the discrete grid of possible s that I considered when running the code.
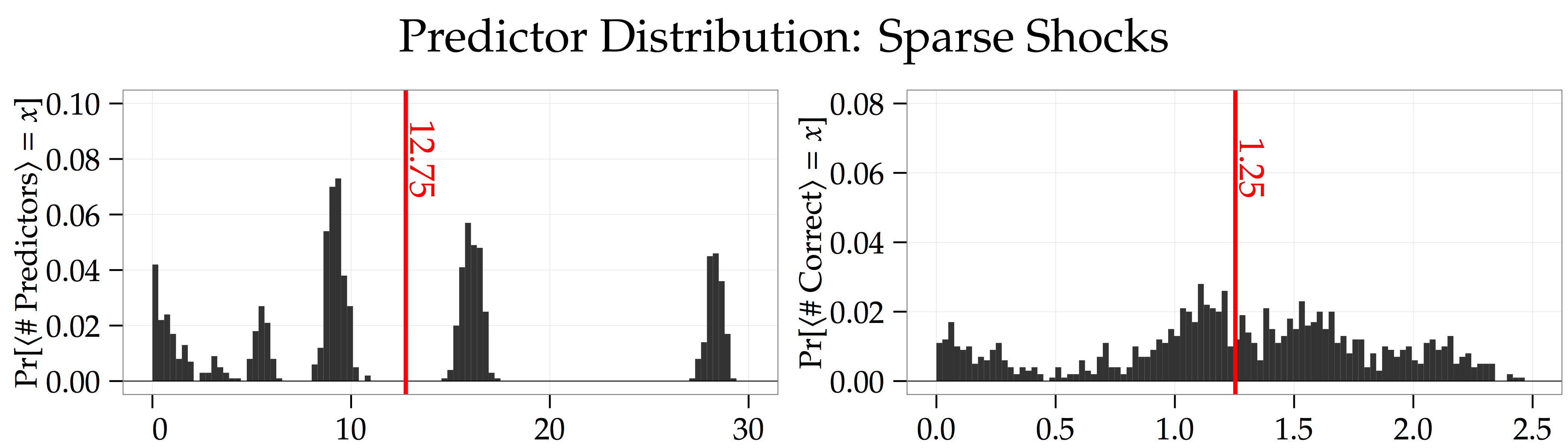
Number of Predictors. Finally, if you look at the panel labeled “Oracle” in the adjusted figure, you’ll notice that the LASSO’s out-of-sample forecasting power is about a third of the true model’s forecasting power,  . This is because the LASSO doesn’t do a perfect job of picking out the sparse signals. The right panel of the figure below shows that the LASSO usually only picks out the most important of these signals. What’s more, the left panel shows that the LASSO also locks onto lots of spurious signals. This result suggests that you might be able to improve the LASSO’s forecasting power by choosing a higher penalty parameter, .
. This is because the LASSO doesn’t do a perfect job of picking out the sparse signals. The right panel of the figure below shows that the LASSO usually only picks out the most important of these signals. What’s more, the left panel shows that the LASSO also locks onto lots of spurious signals. This result suggests that you might be able to improve the LASSO’s forecasting power by choosing a higher penalty parameter, .
5. When Does It Fail?
Placebo Tests. I conclude this post by looking at two alternative simulations where the LASSO shouldn’t add any forecasting power. In the first alternative setting, there are no shocks. That is, the returns for the stocks are simulated using the model below,
(7) 
In the second setting, there are too many shocks:  . The figures below show that, in both these settings, the LASSO doesn’t add any forecasting power. Thus, running these simulations offers a pair of nice placebo tests showing that the LASSO really is picking up sparse signals in the cross-section of returns.
. The figures below show that, in both these settings, the LASSO doesn’t add any forecasting power. Thus, running these simulations offers a pair of nice placebo tests showing that the LASSO really is picking up sparse signals in the cross-section of returns.


You must be logged in to post a comment.