1. Motivation
Imagine you’re an arbitrageur and you see a sequence of abnormal returns:
(1) ![\begin{align*} \mathit{ra}_t \overset{\scriptscriptstyle \mathrm{iid}}{\sim} \begin{cases} +1 &\text{w/ prob } \sfrac{1}{2} \cdot (1 + \alpha) \\ -1 &\text{w/ prob } \sfrac{1}{2} \cdot (1 - \alpha) \end{cases} \qquad \text{with} \qquad \alpha \in [-1,1] \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-2783005c2869f32e2df00a94a7b48c98_l3.svg "Rendered by QuickLaTeX.com")
Here,  denotes the stock’s average abnormal returns, so the stock’s mispriced if
denotes the stock’s average abnormal returns, so the stock’s mispriced if  . Suppose you don’t initially know whether or not the stock is priced correctly, whether or not
. Suppose you don’t initially know whether or not the stock is priced correctly, whether or not  , but as you see more and more data you refine your beliefs,
, but as you see more and more data you refine your beliefs,  . In fact, your posterior variance disappears as
. In fact, your posterior variance disappears as  :1
:1
(2) 
So, such pricing errors can’t persist forever unless there’s some limit to arbitrage, like trading costs or short-sale constraints, to keep you from trading it away.
However, pricing errors often don’t persist period after period. Instead, they tend to arrive sporadically, affecting the first period’s returns, skipping the next two periods’ returns, affecting the fourth and fifth periods’ returns, and so on… What’s more, arbitrageurs don’t have access to an oracle. They don’t know ahead of time which periods are affected and which aren’t. They have to figure this information out on the fly, in real time. In this post, I show that arbitrageurs with an infinite time series may never be able to identify a sporadic pricing error because they don’t know ahead of time where to look.
2. Sporadic Errors
What does it mean to say that a pricing error is sporadic? Suppose that, in each trading period, there is a key state variable,  . If
. If  , then the stock’s abnormal returns are drawn from a distribution with ; whereas, if
, then the stock’s abnormal returns are drawn from a distribution with ; whereas, if  , then the stock’s abnormal returns are drawn from a distribution with . Let
, then the stock’s abnormal returns are drawn from a distribution with . Let  denote the probability that in a given trading period:
denote the probability that in a given trading period:
(3) ![\begin{align*} \theta_t &= \mathrm{Pr}\left[ \, s_t = 1 \, \middle| \, s_0 = 1 \, \right] \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-43e748af6bed583238edcf939211df4c_l3.svg "Rendered by QuickLaTeX.com")
So,  for every
for every  in the example above where the stock always has a mean abnormal return of . By contrast, if
in the example above where the stock always has a mean abnormal return of . By contrast, if  in every trading period, then the pricing error is sporadic.
in every trading period, then the pricing error is sporadic.
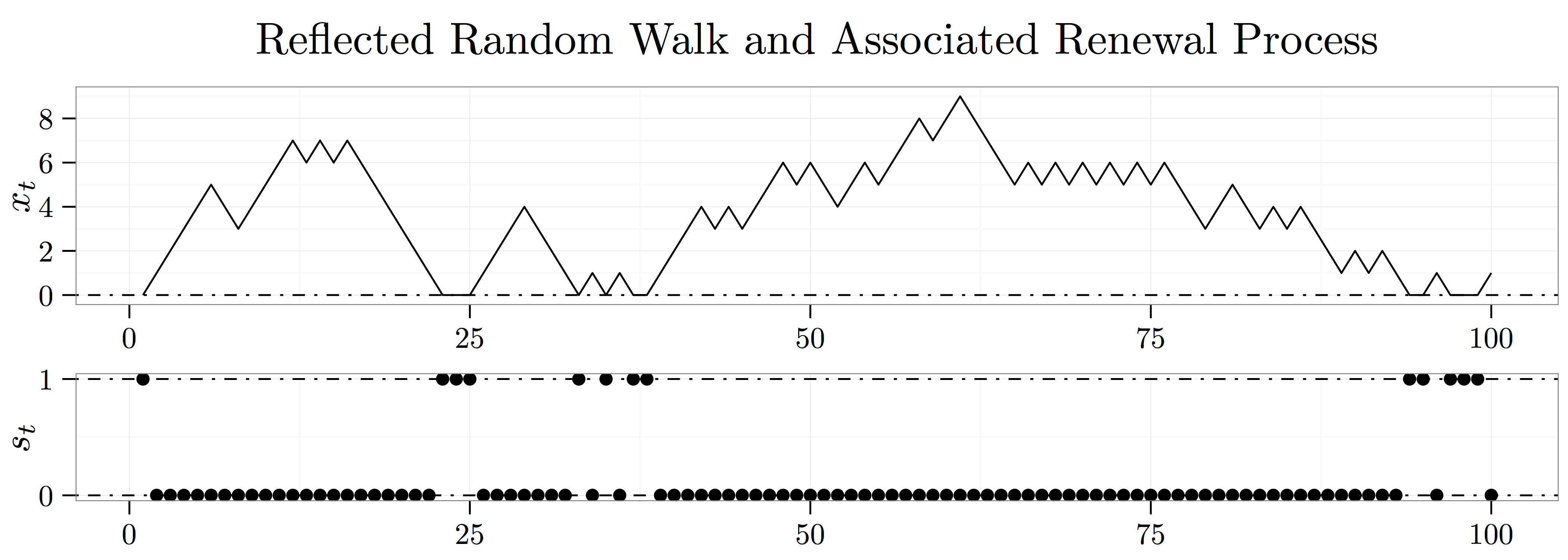
You can think about this state variable in a number of ways. For instance, perhaps the market conditions have to be just right for the arbitrage opportunity to exist. In the figure above, I model the distance to this Goldilocks zone as a reflected random walk,  :
:
(4) 
Then, every time hits the origin, the mispricing occurs. Thought of in this way, the state variable represents a renewal process.
3. Inference Problem
Suppose you see an infinitely long time series of abnormal returns. Let  denote the distribution of abnormal returns when always, and let
denote the distribution of abnormal returns when always, and let  denote the distribution of abnormal returns when sometimes. So, if abnormal returns are drawn from
denote the distribution of abnormal returns when sometimes. So, if abnormal returns are drawn from  , then there are no pricing errors; whereas, if abnormal returns are drawn from
, then there are no pricing errors; whereas, if abnormal returns are drawn from  , then there are some pricing errors. Here’s the question: When can you conclusively tell whether the data was drawn from rather than ?
, then there are some pricing errors. Here’s the question: When can you conclusively tell whether the data was drawn from rather than ?
If a trader can perfectly distinguish between the pair of probability distributions, and , then, when you give him any randomly selected sequence of abnormal returns,  , he will look at it and go, “That’s from distribution .”, or “That’s from distribution .” He will never be stumped. He will never need more information. Mutual singularity is the mathematical way of phrasing this simple idea. Let
, he will look at it and go, “That’s from distribution .”, or “That’s from distribution .” He will never be stumped. He will never need more information. Mutual singularity is the mathematical way of phrasing this simple idea. Let  denote the set of all possible infinite abnormal return sequences:
denote the set of all possible infinite abnormal return sequences:
(5) 
We say that a pair of distributions, and , are mutually singular if there exist disjoint sets,  and
and  , whose union is such that
, whose union is such that  for all sequences
for all sequences  while
while  for all sequences
for all sequences  . If and are mutually singular then we can write
. If and are mutually singular then we can write  . For example, if the alternative hypothesis is that
. For example, if the alternative hypothesis is that  every day, then since we know that all abnormal return sequences drawn from have a mean of exactly
every day, then since we know that all abnormal return sequences drawn from have a mean of exactly  as while all abnormal return sequences drawn from have a mean of exactly as .
as while all abnormal return sequences drawn from have a mean of exactly as .
At the other extreme, you could imagine a trader being completely unable to tell a pair of distributions apart. It might be the case that any sequence of abnormal returns that is off limits in distribution is also off limits in distribution . That is, you might never be able to find a sequence of returns that you could use to reject the null hypothesis. Absolute continuity is the mathematical way of phrasing this idea. A distribution is absolutely continuous with respect to if implies that  . This is written as
. This is written as  .
.
In this post I want to know: for what kind of sporadic pricing errors is  ? When can a trader never be completely sure that he’s seen an pricing error and not just an unlikely set of market events?
? When can a trader never be completely sure that he’s seen an pricing error and not just an unlikely set of market events?
4. Main Results
Now for the two main results. Harris and Keane (1997) show that, i) if the pricing error happens frequently enough, then traders can identify it regardless of how large it is:
(6) 
For instance, suppose that a stock’s abnormal returns are drawn from a distribution with a really small  every single period (i.e., for all ). Then, just like standard statistical intuition would suggest, traders with enough data will eventually identify this tiny pricing error since
every single period (i.e., for all ). Then, just like standard statistical intuition would suggest, traders with enough data will eventually identify this tiny pricing error since  .
.
By contrast, ii) if the pricing error is small and rare enough, then traders with an infinite amount of data will never be able to reject . They will never be able to conclusively know that there was a pricing error:
(7) 
Again, means that traders can’t find a sequence of abnormal returns which would only have been possible under . This is a bit of a strange result. To illustrate, suppose that you and I both see a suspicious abnormal return at time  . But, while you think it’s due to a sporadic arbitrage opportunity of size , I think it was just a random market fluctuation. If the probability that this pricing error recurs shrinks over time,
. But, while you think it’s due to a sporadic arbitrage opportunity of size , I think it was just a random market fluctuation. If the probability that this pricing error recurs shrinks over time,
(8) 
then no amount of additional data will enable us to conclusively settle our argument. There can be no smoking gun. We’ll just have to agree to disagree. This result runs against the standard Harsanyi doctrine which says that people who see the same information will end up with the same beliefs.
5. Proof Sketch
I conclude by sketching the proof for part ii) of Harris and Keane (1997)‘s main result: if the pricing error is sufficiently small and rare, then traders will never be able to reject . To do this, I need to be able to show that, if  , then every sequence of abnormal returns with the property that also has the property that . The easiest way to do this is to look at the behavior of the following integral:
, then every sequence of abnormal returns with the property that also has the property that . The easiest way to do this is to look at the behavior of the following integral:
(9) 
If it’s finite, then every time it must also be the case that . Otherwise, you’d be dividing a positive number,  , by .
, by .
So, let’s examine this integral. At its core, this integral is just a weighted average of the number of times that a mispricing should occur under since  :
:
(10) 
If we define  as the number of periods in which there is a pricing error,
as the number of periods in which there is a pricing error,
(11) 
then we can further bound this integral as follows since  :
:
(12) ![\begin{align*} \int_{\{0,1\}^\infty} \prod_{t=1}^\infty (1 + \alpha^2 \cdot s_t^2 ) \cdot d\Theta(\mathbf{s}) &\leq \sum_{j=1}^\infty (1 + \alpha^2)^j \cdot \mathrm{Pr}[J = j] &\leq \sum_{j=1}^\infty (1 + \alpha^2)^j \cdot \mathrm{Pr}[J > 1]^{j-1} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-f55eb305f7ee0fac3778881d9d3e8370_l3.svg "Rendered by QuickLaTeX.com")
However, we know that the probability that there is at least  period where a pricing error occurs is just the inverse of the expected number of periods in which a pricing error occurs:
period where a pricing error occurs is just the inverse of the expected number of periods in which a pricing error occurs:
(13) ![\begin{align*} \frac{1}{\mathrm{Pr}[J > 1]} = \sum_{t=0}^\infty \theta_t^2 \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-b9b2ceda429fd5959cbf49727a3516b5_l3.svg "Rendered by QuickLaTeX.com")
So, we have our desired result. That is, whenever:
(14) 
- e.g., see the computation for the beta-binomial model. ↩
You must be logged in to post a comment.