1. Motivation
Evolutionarily Slow. In modern financial markets, people simultaneously trade the exact same assets on vastly different timescales. For example, a Jegadeesh and Titman (1993)-style momentum portfolio turns over half its holdings once every  months. By contrast, Kirilenko, Kyle, Samadi, and Tuzun (2014) estimate that “high-frequency traders (HFTs) reduce half of their net holdings in
months. By contrast, Kirilenko, Kyle, Samadi, and Tuzun (2014) estimate that “high-frequency traders (HFTs) reduce half of their net holdings in  seconds.” These two horizons differ by
seconds.” These two horizons differ by  orders of magnitude:
orders of magnitude:
(1) 
This is a big number. To put it in perspective, there have only been around  generations since the human/chimpanzee divergence. See MacKay (2003, C4). So, in a quite literal sense, momentum traders are evolutionarily slow by HFT standards. This difference in timescales has a couple of important implications.
generations since the human/chimpanzee divergence. See MacKay (2003, C4). So, in a quite literal sense, momentum traders are evolutionarily slow by HFT standards. This difference in timescales has a couple of important implications.
Different Strokes. First, because their respective timescales are so different, short- and long-run traders value assets differently. One reason is purely mechanical: short-run traders have to close out their positions at the end of each day. Why should they be interested in a company’s quarterly cash flows? Another reason is more subtle: a trader’s timescale affects the kind of information he can process. Short-run traders operate at speeds faster than any human can handle, so these traders have to focus on machine-readable information; whereas, long-run traders operate on more human timescales, so these traders tend to focus on soft information. Traders at different timescales also have very different educational backgrounds. As the pace of trading gets faster, traders become more likely to have a background in mathematics, computer science, or engineering than a background in economics, finance, or accounting.
Predictable Demand. Second, because long-run traders’ timescale is so slow, their order flow will look slightly predictable to short-run traders. If long-run traders space their orders out over the course of a month, then demand in the previous minute is going to give short-run traders a little bit of information about what demand will be like in the next minute. The SEC points out in a 2010 report that short-run traders often use “sophisticated pattern recognition software to ascertain from publicly available information the existence of a large buyer (seller)” or “ping different market centers in an attempt to locate and trade in front of large buyers (sellers).” Even if you didn’t know that the last common ancestor we shared with chimpanzees would eventually evolve into humans in the long-run, at each step along the way, you could look at two parents and still have a pretty good idea of what their offspring were going to be like.
What It All Means. These two observations imply that short-run traders will want to adjust their own trading behavior due to the presence of long-run traders and vice versa, affecting the returns we observe at each horizon. Put another way, a pair of assets with the same fundamentals might realize different returns because their traders operate at different timescales. This post outlines an asset-pricing model studying precisely this effect. It’s an overview of the model in my paper, When Fast Trading Looks Like Priced Noise.
2. Market Structure
Long-Run Value. There are  trading periods and a single asset that has a long-run fundamental value of
trading periods and a single asset that has a long-run fundamental value of
(2) 
For instance, you might think about  as a liquidating dividend. There is the same amount of variance in the long-run fundamental value regardless of the number of trading periods. After all, a factory’s production doesn’t get more erratic if people start to trade shares in the company that owns it more quickly.
as a liquidating dividend. There is the same amount of variance in the long-run fundamental value regardless of the number of trading periods. After all, a factory’s production doesn’t get more erratic if people start to trade shares in the company that owns it more quickly.
Short-Run Value. This asset also realizes short-run, transient, value shocks
(3) 
that are irrelevant in the long-run. For instance, you might think about each  as a payment from an exchange for providing liquidity. Importantly, short-run traders care about both the permanent and the transient parts of an asset’s short-run value when choosing their portfolio holdings,
as a payment from an exchange for providing liquidity. Importantly, short-run traders care about both the permanent and the transient parts of an asset’s short-run value when choosing their portfolio holdings,
(4) 
Algorithmic traders have to close out their positions overnight. So, they can’t justify an awful P&L statement on Monday by telling their MD that holding the position for a month will return it to the black.
Pricing Rule. Each period, uninformed market makers set the asset’s price equal to their conditional expectation of the asset’s long-run fundamental value after observing the aggregate demand for the asset,
(5) ![\begin{align*} p_t = \mathrm{E}[v|a_t] = \lambda_0 + \lambda_a \times a_t \qquad \text{with} \qquad a_t = x_t + y + z_t. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-e69581621ae388aa0c1d2451167da1e3_l3.svg "Rendered by QuickLaTeX.com")
Here,  denotes the number of shares bought by the short-run trader,
denotes the number of shares bought by the short-run trader,  denotes the number of shares bought by the long-run trader, and
denotes the number of shares bought by the long-run trader, and  denotes the number of shares bought by noise traders.
denotes the number of shares bought by noise traders.
To offset their expected losses from trading with more informed agents, market makers charge a fee,  , to each group of traders where
, to each group of traders where
(6) ![\begin{align*} \kappa &= \mathrm{E}[ \, {\textstyle \frac{1}{\sigma_a} \cdot \sum_{t=1}^T} (v - p_t) \cdot a_t \, ]. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-103a71cde792bb4771a416cc32ddf383_l3.svg "Rendered by QuickLaTeX.com")
So, the monthly price we observe in the data is  . As Brennan and Subrahmanyam (1996) write, “privately informed investors create significant illiquidily costs for uninformed investors, implying that the required rates of return should be higher for securities that are relatively illiquid.” A fee is a simple way of building this price effect into the model. Alternatively, you could add in this price effect by getting rid of the market maker and modeling risk-averse informed traders facing imperfect competition a la Kyle (1989), but this approach leads to a much more complicated analysis without any additional insight.
. As Brennan and Subrahmanyam (1996) write, “privately informed investors create significant illiquidily costs for uninformed investors, implying that the required rates of return should be higher for securities that are relatively illiquid.” A fee is a simple way of building this price effect into the model. Alternatively, you could add in this price effect by getting rid of the market maker and modeling risk-averse informed traders facing imperfect competition a la Kyle (1989), but this approach leads to a much more complicated analysis without any additional insight.
3. Short-Run Traders
Optimization Problem. There are groups of short-run traders that each trade in a single period. Because long-run traders trade so gradually compared to short-run traders, their demand will be slightly predictable and, thus, give away some of their private information about long-run fundamentals. So, prior to trading, short-run traders observe not only the combined short-run value of the asset,  , but also a signal about the asset’s long-run fundamental value,
, but also a signal about the asset’s long-run fundamental value,  . These traders then solve the static optimization problem below,
. These traders then solve the static optimization problem below,
(7) ![\begin{align*} \max_{x_t} \, \mathrm{E}\left[ \, (\tilde{v}_t - p_t) \cdot x_t \, \middle| \, \tilde{v}_t, \, s_t \, \right]. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-41c77c3ba6c7c65b41eeb9242d9a39bd_l3.svg "Rendered by QuickLaTeX.com")
The short-run traders’ signal each period is centered around the asset’s long-run fundamental value and gets more precise when long-run traders trade more aggressively,
(8) 
where  is the long-run traders’ demand response which I define in the next section. So, the more long-run traders act on their private information, the more this information leaks out to short-run traders.
is the long-run traders’ demand response which I define in the next section. So, the more long-run traders act on their private information, the more this information leaks out to short-run traders.
Demand Rule. I look for a linear demand rule:
(9) 
The coefficient  has units of
has units of  and captures how many shares a short-run trader will demand on average. The coefficient
and captures how many shares a short-run trader will demand on average. The coefficient  has units of
has units of  and captures how many additional shares a short-run trader will demand in the current period if the total short-run value increases by
and captures how many additional shares a short-run trader will demand in the current period if the total short-run value increases by  per share. The coefficient
per share. The coefficient  also has units of but captures how many additional shares a short-run trader will demand if his signal about the long-run fundamental value of the asset gets per share more optimistic.
also has units of but captures how many additional shares a short-run trader will demand if his signal about the long-run fundamental value of the asset gets per share more optimistic.
4. Long-Run Traders
Optimization Problem. There is a single group of long-run traders who observe the long-run fundamental value of the asset, . These traders solve the static optimization problem below,
(10) ![\begin{align*} \max_y \, \mathrm{E}\left[ \, {\textstyle \sum_{t=1}^T} (v - p_t) \cdot y \, \middle| \, v \, \right]. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-fdeac79f509f572cbc75813debbd988e_l3.svg "Rendered by QuickLaTeX.com")
Long-run traders have to demand the exact same number of shares every single time. This is what makes them “long-run” and why there is no time subscript on their demand, . For instance, you can think about long-run traders as traders who slowly adjust their positions using instruments like time-weighted average pricing rules, which automatically execute trades over a predetermined timeframe.
Demand Rule. Again, I look for a linear demand rule:
(11) 
The coefficient  has units of and captures how many shares the long-run trader will demand on average. The coefficient has units of and captures how many additional shares the long-run trader will demand in each trading period if the long-run fundamental value increases by per share.
has units of and captures how many shares the long-run trader will demand on average. The coefficient has units of and captures how many additional shares the long-run trader will demand in each trading period if the long-run fundamental value increases by per share.
5. Solving the Model
Short-Run Demand. When you account for long-run trader’s demand rule, short-run traders’ problem morphs into:
(12) ![\begin{align*} \max_{x_t} \, \mathrm{E}\left[ \, (\tilde{v}_t - \lambda_0 - \lambda_a \cdot \{ x_t + \gamma_0 + \gamma_v \cdot v + z_t\}) \cdot x_t \, \middle| \, \tilde{v}_t, \, s_t \, \right]. \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-772c2a4581cf86c343e049a9ef3bc236_l3.svg "Rendered by QuickLaTeX.com")
After observing the combined short-run asset value and their signal about long-run fundamental value, short-run traders have posterior beliefs of
(13) ![\begin{align*} \mathrm{E}[v|\tilde{v}_t,s_t] &= \psi \cdot \omega \cdot \mu_v + (1 - \psi) \cdot \omega \cdot \tilde{v}_t + (1 - \omega) \cdot s_t \\ \text{and} \quad \mathrm{Var}[v|\tilde{v}_t,s_t] &= \psi^2 \cdot \omega^2 \cdot \sigma_v^2 + (1 - \psi)^2 \cdot \omega^2 \cdot \sigma_{\epsilon}^2 + (1 - \omega)^2 \cdot {\textstyle \frac{\sigma_z^2}{\gamma_v^2}} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-cc5fc296fb599db9dc5da7e36160981d_l3.svg "Rendered by QuickLaTeX.com")
where  and
and  . Thus, the short-run traders’ optimal demand is given by:
. Thus, the short-run traders’ optimal demand is given by:
(14) 
Long-Run Demand. When you account for short-run traders’ demand rule, the long-run trader’s problem turns into:
(15) ![\begin{align*} \max_y \, \mathrm{E}\Big[ \, T \cdot \Big( \, v - \{ \lambda_0 + \lambda_a \cdot (\beta_0 + \beta_{\tilde{v}} \cdot \underset{=v}{{\textstyle \frac{1}{T} \cdot \sum_{t=1}^T} \tilde{v}_t} + \beta_s \cdot \underset{=v}{{\textstyle \frac{1}{T} \cdot \sum_{t=1}^T} s_t} + y + \underset{=0}{{\textstyle \frac{1}{T} \cdot \sum_{t=1}^T} z_t}) \} \, \Big) \cdot y \, \Big| \, v \, \Big] \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-e697f4dbdd461e93dbd829ab2d9e55a6_l3.svg "Rendered by QuickLaTeX.com")
Notice that, as the number of short-run trading periods grows large,  , the long-run trader’s problem becomes completely deterministic because they only care about the average price. From the point of view of the long-run trader, transient asset-value fluctuations blur together and average out in the same way that you can’t tell with the naked eye that incandescent lights actually flicker at 60Hz. Thus, the long-run trader’s optimal demand is given by:
, the long-run trader’s problem becomes completely deterministic because they only care about the average price. From the point of view of the long-run trader, transient asset-value fluctuations blur together and average out in the same way that you can’t tell with the naked eye that incandescent lights actually flicker at 60Hz. Thus, the long-run trader’s optimal demand is given by:
(16) 
The short-run traders’ demand coefficients still show up in the long-run trader’s demand rule. So, even though all of the short-run, transient, value shocks average out, there are still echoes of the short-run traders’ demand rule in the long-run.
System of Equations. Given the short- and long-run traders’ optimal demand rules, the market maker in each trading period sets the price equal to his conditional expectation of the asset’s long-run fundamental value after observing the aggregate demand:
(17) 
Thus, the equilibrium slope coefficients are defined by the following system of  equations and unknowns:
equations and unknowns:
(18) 
After solving the slop coefficients, the equilibrium level coefficients are then pinned down by a further system of  equations and unknowns:
equations and unknowns:
(19) 
6. Comparative Statics
Equilibrium Parameters. I solve for the equilibrium parameters numerically (code). The figure below shows how the slope parameters vary as I increase the ratio of short- to long-run asset-value volatility from  to
to  . When , there are no short-run, transient, value shocks and the model collapses to the standard Kyle (1985) model. As
. When , there are no short-run, transient, value shocks and the model collapses to the standard Kyle (1985) model. As  increases, there are more short-run value shocks for short-run traders to trade on (upward-sloping curve in left-most panel labeled ), meaning that there is effectively more noise trading. As a result, long-run traders trade more aggressively on their private information (upward-sloping curve in right-center panel label ) and market makers respond less aggressively to aggregate demand shocks (downward-sloping curve in right-most panel labeled
increases, there are more short-run value shocks for short-run traders to trade on (upward-sloping curve in left-most panel labeled ), meaning that there is effectively more noise trading. As a result, long-run traders trade more aggressively on their private information (upward-sloping curve in right-center panel label ) and market makers respond less aggressively to aggregate demand shocks (downward-sloping curve in right-most panel labeled  ).
).

Expected Profits. The figure below plots each trader type’s expected profit as I again increase the ratio of short- to long-run asset-value volatility from to . Because the long-run trader’s demand looks slightly predictable to short-run traders, the long-run trader can’t fully exploit the noise that short-run traders provide. So, the long-run trader can’t fully exploit the camouflage provided by short-run traders’ extra demand. Nevertheless, the long-run trader’s expected profit each trading period still goes up when there is more short-run trading activity (upward-sloping curve in left-center panel). This is exactly the point Cliff Asness and Michael Mendelson make in their Wall Street Journal op-ed when they write that, “How do we feel about high-frequency trading? We think it helps us. It seems to have reduced our costs and may enable us to manage more investment dollars.”

 , a trader adhering to prospect theory values the payouts relative to a reference point and places extra weight on bad outcomes.
, a trader adhering to prospect theory values the payouts relative to a reference point and places extra weight on bad outcomes. 
 .
. and
and  , as pictured below:
, as pictured below: 
 would then assign this lottery a certainty-equivalent value:
would then assign this lottery a certainty-equivalent value:
 , his certainty-equivalent value for the lottery is less than the expected value of the lottery,
, his certainty-equivalent value for the lottery is less than the expected value of the lottery,  .
.
 .
. -period version of the binomial model above where every period the payout is equally likely to either decrease or increase by
-period version of the binomial model above where every period the payout is equally likely to either decrease or increase by  .
. 
 is either
is either
 , we can then write the certainty-equivalent value of the time
, we can then write the certainty-equivalent value of the time 
 at the certainty-equivalent value of
at the certainty-equivalent value of  .
.

 , to case where the trader also gets an arbitrary intermediate signal,
, to case where the trader also gets an arbitrary intermediate signal,  , from some distribution
, from some distribution  , which moves his beliefs:
, which moves his beliefs:
 and
and  such that
such that
 . Under prospect theory, traders don’t like to be given intermediate updates about their portfolio.
. Under prospect theory, traders don’t like to be given intermediate updates about their portfolio. from the geometric-Brownian-motion process below:
from the geometric-Brownian-motion process below:
 . But, how would a trader value the payout if he were information averse and only looked at the process every
. But, how would a trader value the payout if he were information averse and only looked at the process every  minutes,
minutes,  ? So, for example, if the terminal payout is
? So, for example, if the terminal payout is  minutes away and he checks the process every minute,
minutes away and he checks the process every minute,  , then
, then 
 , then
, then  .
.
 minutes, then he runs the risk of experiencing painful temporary losses that he wouldn’t otherwise notice. As a result, even though the actual valuation is growing at a rate of
minutes, then he runs the risk of experiencing painful temporary losses that he wouldn’t otherwise notice. As a result, even though the actual valuation is growing at a rate of  per minute, the trader’s effective valuation is only growing at a rate of
per minute, the trader’s effective valuation is only growing at a rate of  per minute after accounting for the additional anguish he feels. Thus, the value of the lottery at time
per minute after accounting for the additional anguish he feels. Thus, the value of the lottery at time 
![\lim_{\ell \to \infty}[\mu_{\ell}] = \mu](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-7c5ed1f37357ce140405516108488c1b_l3.svg "Rendered by QuickLaTeX.com") and
and ![\frac{\partial}{\partial \theta}[\mu_{\ell}] < 0](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-09e290c9266bcdbfd191b3886c7f1e67_l3.svg "Rendered by QuickLaTeX.com") . That is, if a trader never checks in on the lottery, then his valuation is the same as the risk-neutral valuation.
. That is, if a trader never checks in on the lottery, then his valuation is the same as the risk-neutral valuation.
 ; what fraction of his wealth to invest in the risky asset,
; what fraction of his wealth to invest in the risky asset, 
 , he can’t be insolvent
, he can’t be insolvent  ,
,  is his intertemporal elasticity of substitution,
is his intertemporal elasticity of substitution,  is his discount rate, and
is his discount rate, and  is the risk-free rate.
is the risk-free rate. as the amount that the agent has to save in order to finance his deterministic consumption from time
as the amount that the agent has to save in order to finance his deterministic consumption from time 

 of his wealth in the risky asset.
of his wealth in the risky asset.![\begin{align*} \frac{\partial}{\partial \log(\ell)}[\mu_{\ell^\star}] &= \left( \, \frac{\rho}{1 - \alpha} - \mu_{\ell^\star} \, \right) \cdot \left( \, 1 - \frac{f(\sfrac{\rho}{(1-\alpha)} - r,\ell^\star)}{f(\sfrac{\rho}{(1-\alpha)} - \mu_{\ell^\star},\ell^\star)} \, \right), \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-41b437595d33d0b3966c43448b7bc208_l3.svg "Rendered by QuickLaTeX.com")
 . They find that the agent is less attentive when he has a bigger disappointment aversion parameter,
. They find that the agent is less attentive when he has a bigger disappointment aversion parameter,  , and when the risky asset’s payout is more volatile,
, and when the risky asset’s payout is more volatile,  .
. , at the end of the period. As is usually the case, this payout is normally distributed,
, at the end of the period. As is usually the case, this payout is normally distributed,
 . In this market, there are
. In this market, there are  total traders, of which
total traders, of which  are informed while
are informed while  are uninformed. Let
are uninformed. Let  denote each informed trader’s demand for the asset in units of shares per trader and let
denote each informed trader’s demand for the asset in units of shares per trader and let  denote each uninformed trader’s demand in units of shares per trader. Thus, if there are
denote each uninformed trader’s demand in units of shares per trader. Thus, if there are  total shares of the asset available for purchase, then the market clearing condition is:
total shares of the asset available for purchase, then the market clearing condition is:
 , to learn the fundamental value of the asset,
, to learn the fundamental value of the asset, ![\begin{align*} - \, \mathrm{E}\left( \, e^{- \phi \cdot [ \, (\hat{v} - p) \cdot x_i - \lambda \, ]} \, \middle| \, \hat{v} \, \right), \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-a1b7cf7f29360a162ebd8e0868b7d9e4_l3.svg "Rendered by QuickLaTeX.com")
 is their risk-aversion parameter in units of traders per dollar. Let’s guess that each informed trader’s demand rule is linear in the fundamental asset value,
is their risk-aversion parameter in units of traders per dollar. Let’s guess that each informed trader’s demand rule is linear in the fundamental asset value,
 has units of shares per trader and
has units of shares per trader and  has units of squared shares per dollar per trader. It’s possible to verify later that this linear symmetric demand rule for the informed traders is indeed optimal.
has units of squared shares per dollar per trader. It’s possible to verify later that this linear symmetric demand rule for the informed traders is indeed optimal. , that they’d be willing to trade—just like in
, that they’d be willing to trade—just like in 


 is dimensionless, and
is dimensionless, and  has units of dollars per squared share. If the pricing rule is indeed linear—and, it’s easy to see that this is the case after solving model—then this means price gives unbiased signal about the fundamental value of the asset,
has units of dollars per squared share. If the pricing rule is indeed linear—and, it’s easy to see that this is the case after solving model—then this means price gives unbiased signal about the fundamental value of the asset,
 . Thus, conditional on observing the market-clearing price, uninformed traders have posterior beliefs about the fundamental value of the asset,
. Thus, conditional on observing the market-clearing price, uninformed traders have posterior beliefs about the fundamental value of the asset,![\begin{align*} \begin{matrix} \mathrm{Var}(\hat{v}|p) = (1 - \kappa) \times \sigma_v^2 & \quad \text{and} \quad & \mathrm{E}(\hat{v}|p) = \kappa \times \sfrac{1}{\beta_1} \cdot (p - [\beta_0 - \beta_2 \cdot \mu_s]), \end{matrix} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-554081e7dc7fe1c0b86ee183c641a91b_l3.svg "Rendered by QuickLaTeX.com")
 is a dimensionless constant.
is a dimensionless constant.



 . If we plug this formula for the price into the
. If we plug this formula for the price into the  th informed trader’s optimization problem,
th informed trader’s optimization problem, 

 after noticing that
after noticing that  . With these values in hand, we can also solve for
. With these values in hand, we can also solve for 

 , we can characterize each informed trader’s unconditional expectation of his utility as,
, we can characterize each informed trader’s unconditional expectation of his utility as,
 ,
,  , and
, and  are given by:
are given by:


 . In all of the plots below, I use the following parameterization:
. In all of the plots below, I use the following parameterization:  ,
,  ,
,  ,
,  , and
, and  . You can find the code used to create these plots
. You can find the code used to create these plots 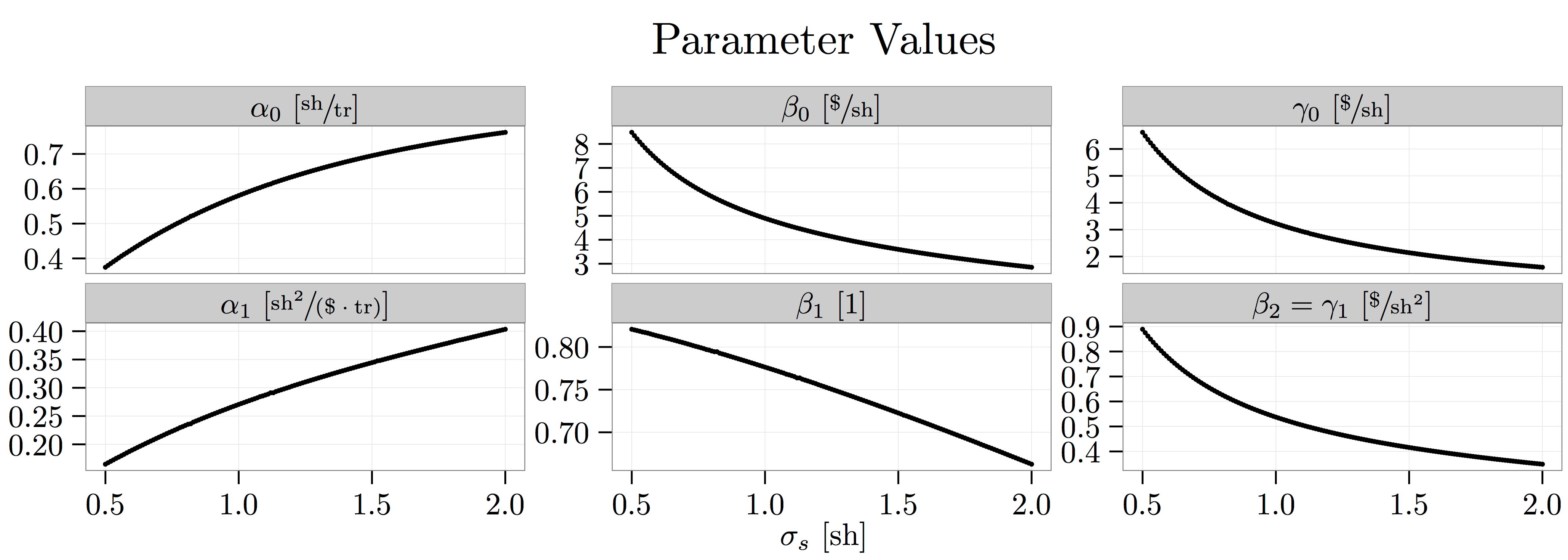

 shares at
shares at  per share,
per share,  shares at
shares at  per share,
per share,  shares at
shares at  per share, and so on. Informed traders choose this menu of price-quantity pairs such that, at each price level, their expected utility gain from holding another share of the stock is exactly offset by the disutility they realize from the extra variance that holding this share adds to their portfolio. Informed traders’ strategic behavior in
per share, and so on. Informed traders choose this menu of price-quantity pairs such that, at each price level, their expected utility gain from holding another share of the stock is exactly offset by the disutility they realize from the extra variance that holding this share adds to their portfolio. Informed traders’ strategic behavior in  , where the payout is composed of two independent parts,
, where the payout is composed of two independent parts,
 ,
,  , and
, and  for some
for some  . Here,
. Here,  is the knowable component of the asset’s payout, and
is the knowable component of the asset’s payout, and  is the idiosyncratic component of the asset’s payout. So, for example, if
is the idiosyncratic component of the asset’s payout. So, for example, if  , then the half of the variation in the asset’s payout can be learned and half is due to the accidents of life.
, then the half of the variation in the asset’s payout can be learned and half is due to the accidents of life. shares.” While the informed trader has private information about the value of the asset and uses this information when trading, the noise trader just submits random orders,
shares.” While the informed trader has private information about the value of the asset and uses this information when trading, the noise trader just submits random orders,  . The challenge facing the market maker is that she only gets to see aggregate order flow,
. The challenge facing the market maker is that she only gets to see aggregate order flow, 
 , to demand from the market maker,
, to demand from the market maker,

 , and the informed trader’s demand rule,
, and the informed trader’s demand rule,  , are linear. We’ll see shortly that these guesses are correct.
, are linear. We’ll see shortly that these guesses are correct.
 , just as we guessed.
, just as we guessed. where
where  . But, this means that equilibrium
. But, this means that equilibrium  is just a regression coefficient with the following functional form:
is just a regression coefficient with the following functional form:
 gives the remaining coefficients:
gives the remaining coefficients:
 ) when there is more noise trading (i.e., when
) when there is more noise trading (i.e., when  ). For more detailed analysis, see my earlier posts on the
). For more detailed analysis, see my earlier posts on the  . In this model, there are now many informed traders take the equilibrium price as given and solve the optimization problem below,
. In this model, there are now many informed traders take the equilibrium price as given and solve the optimization problem below,
 . Note that this means the traders are now trying to maximize utility rather than profits. Solving this problem, we see that
. Note that this means the traders are now trying to maximize utility rather than profits. Solving this problem, we see that
 . So, informed traders buy shares whenever the equilibrium price is below their signal about the asset’s expected value, and they buy relatively more shares when they are less risk averse and when their information is more precise.
. So, informed traders buy shares whenever the equilibrium price is below their signal about the asset’s expected value, and they buy relatively more shares when they are less risk averse and when their information is more precise. , and use this information to guide their trading. Each of these uninformed traders solves the same optimization problem as the informed traders,
, and use this information to guide their trading. Each of these uninformed traders solves the same optimization problem as the informed traders,
 is the informed traders’ risk-aversion parameter in units of
is the informed traders’ risk-aversion parameter in units of 
 .
.
 , where
, where  has units of
has units of  ,
,  is dimensionless, and
is dimensionless, and  . Thus, if the uninformed traders only condition on the price of the risky asset when making their portfolio choice, they will have the following signal about
. Thus, if the uninformed traders only condition on the price of the risky asset when making their portfolio choice, they will have the following signal about 

 , which represents how much weight the uninformed traders put on the price signal. When
, which represents how much weight the uninformed traders put on the price signal. When  , uninformed traders learn a lot from the price; whereas, when
, uninformed traders learn a lot from the price; whereas, when  , uninformed traders learn very little from the price.
, uninformed traders learn very little from the price.

 ,
,
 . Matching the coefficients and solving then yields the equilibrium values
. Matching the coefficients and solving then yields the equilibrium values
 ,
,  ,
,  ,
,  ,
,  , and
, and  . For each outcome variable, I look at how the predictions of each model as I vary the quality of the informed traders’ information,
. For each outcome variable, I look at how the predictions of each model as I vary the quality of the informed traders’ information,  , the level of the informed traders’ risk aversion,
, the level of the informed traders’ risk aversion,  , and the volatility of noise traders’ demand,
, and the volatility of noise traders’ demand,  , from
, from 





 , in each model. That is, on average, how much higher is the price when the informed traders’ private signal is
, in each model. That is, on average, how much higher is the price when the informed traders’ private signal is 
 . So, if you want to make predictions linking the information content of prices to noise-trader-demand volatility, you’d better use
. So, if you want to make predictions linking the information content of prices to noise-trader-demand volatility, you’d better use 

 , and the volatility of noise-trader demand,
, and the volatility of noise-trader demand, 
 , from the daily regression
, from the daily regression

 . Over the period from January 1965 to December 2012, I estimate that a trading strategy which is long the stocks with higher-than-average idiosyncratic-return volatility in the previous month and short the stocks with lower-than-average idiosyncratic-return volatility in the previous month,
. Over the period from January 1965 to December 2012, I estimate that a trading strategy which is long the stocks with higher-than-average idiosyncratic-return volatility in the previous month and short the stocks with lower-than-average idiosyncratic-return volatility in the previous month,
 per month or
per month or  per year.
per year.

 . So, for example, if the candidate variable is the maximum daily return in the previous month as suggested in
. So, for example, if the candidate variable is the maximum daily return in the previous month as suggested in 
 and
and  , then the candidate variable explains both a) which stocks had lots of idiosyncratic-return volatility in the the previous month and b) which stocks realized very low returns in the current month.
, then the candidate variable explains both a) which stocks had lots of idiosyncratic-return volatility in the the previous month and b) which stocks realized very low returns in the current month. and
and ![\begin{align*} \beta &= \mathrm{Cov}[ \, r_{n,t} , \, \widetilde{\mathit{ivol}}_{n,t-1} \, ] \\ &= \mathrm{Cov}\left[ \, r_{n,t}, \, \gamma_t \cdot \widetilde{x}_{n,t-1} + \xi_{n,t-1} \, \right] \\ &= \underbrace{\gamma_t \cdot \mathrm{Cov}\left[ \, r_{n,t}, \, \widetilde{x}_{n,t-1} \, \right]}_{\text{Explained}} + \underbrace{\mathrm{Cov}\left[ \, r_{n,t}, \, \xi_{n,t-1} \, \right]}_{\substack{\text{Everything} \\ \text{Else}}} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-141849093a46a0c6cedb77374c13764f_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} \beta_{E,t} &= \gamma_t \cdot \mathrm{Cov}\left[ \, r_{n,t}, \, \widetilde{x}_{n,t-1} \, \right] = \frac{\gamma_t}{N \cdot \sigma_{x,t-1}} \cdot \sum_n \left( x_{n,t-1} - \mu_{x,t-1} \right) \cdot r_{n,t}, \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-7487460943ffe0cd1c33ef8335e8bbda_l3.svg "Rendered by QuickLaTeX.com")
 . Put differently, a candidate variable explains a lot of the idiosyncratic-return-volatility puzzle if it is a good predictor of idiosyncratic-return volatility,
. Put differently, a candidate variable explains a lot of the idiosyncratic-return-volatility puzzle if it is a good predictor of idiosyncratic-return volatility,  , and it generates negative returns when you trade on it,
, and it generates negative returns when you trade on it,  .
. be a vector of coefficients to be estimated in month
be a vector of coefficients to be estimated in month 
 -dimensional vector of coefficients using the following moment conditions:
-dimensional vector of coefficients using the following moment conditions:
 per month, or about
per month, or about  of the total puzzle.
of the total puzzle.

You must be logged in to post a comment.